AI Strategy for Venture Capital Investors
My inboxes are full of, "We are an AI-based company working on...".
Just a few years ago, everyone was a Fintech company, and then a Blockchain company, now AI is the flavour du jour.
Defining an AI Company
What is an AI company? What is the standard we need to apply to consider a company an "AI company"? Borrowing terminology from Ajay Agarwal's book, we essentially have three types of firms:
1. Point Solutions
2. Application Solutions
3. System Solutions
Let's consider a regular insurance firm as a baseline. They have human actuaries and use Excel, and other such software to even run their actuarial models. They just don't use anything that claims to be AI.
How does AI fit in here?
Point Solutions are usually characterised by their focus on a single function or problem area. An example could be an API to detect fraudulent claims based on patterns that deviate from the norm. This plugs into their existing workflow, possibly even via an Excel add-on.
Application Solutions on the other hand integrate multiple related functionalities or services, going beyond a single task to support a broader set of processes or decision-making needs within a specific context (e.g., marketing, customer relationship management). Lemonade, the insurance firm is a good example of this. While they use AI for many processes, the business model remains recognisable as "insurance".
System Solutions reimagine the entire business model using a new technology. Just as the automobile was not just a faster horse, or a computer wasn't just a faster calculator, in the context of AI, AI isn't just a faster, cheaper human worker.
In the insurance sector, we have the Chinese online-only firm ZhongAn, which uses AI (and relevant supporting infrastructure) to offer insurance products. It represents a system solution by fundamentally transforming traditional insurance models into a fully digital, AI-driven operation. While an 'application solution' improves efficiency on an existing business model, a system solution is a complete re-imagination of it.
As things stand, there are a few trends that we will explore below, which at times are seemingly contradictory, and investors and founders both have to grapple with them.
The AI-Model Cost Paradox
Consider, if you will, an intricate dance, but not one confined to the physical world of dancers and dimly lit halls. Instead, the participants of this dance are named Data Cost, Training Efficiency, and Model Size.
Data Cost
As AI models grow more sophisticated, they require diverse, clean, and labelled datasets. Acquiring such data offers immense competitive advantages, including the ability to block competitors from accessing it. This need is particularly acute for datasets that help train models to understand nuanced human behaviour and complex real-world scenarios. Reddit's S-1 is a wonderful example of this. As Reddit's content refreshes and grows daily, it provides a vast amount of human-generated dataset full of human quirks, biases, and genius. And this is not cheap.
Web 2.0 is over - data is no longer free or cheap. It now resides in a digital Fort Knox, protected by firewalls and $1000/hr lawyers.
Training Efficiency
At the same time, the cost to train models is dropping rapidly.
Advances in hardware, such as GPUs and TPUs, alongside software optimisations and training techniques, have made AI model training more efficient. We now pay less for a model that only a few years ago cost an arm, and a leg.
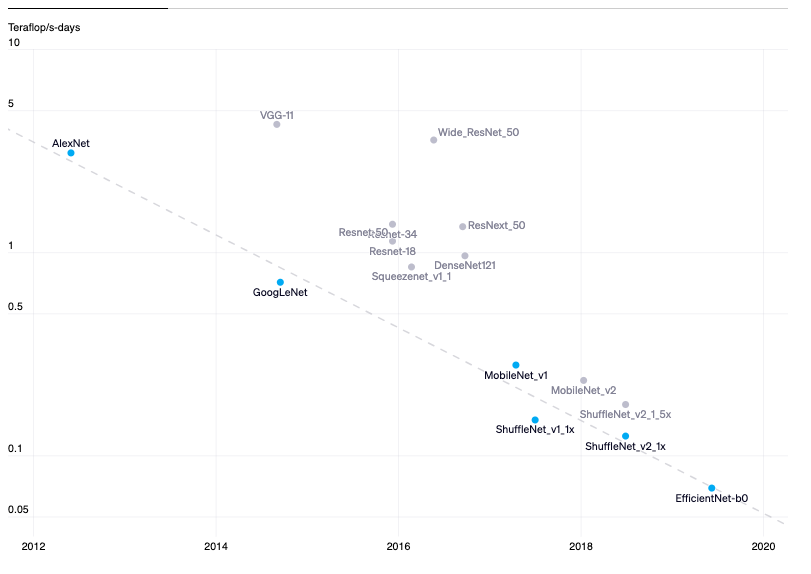
(Image Source: https://openai.com/research/ai-and-efficiency)
This efficiency is measured by how many calculations (Floating-Point Operations per Second, or FLOP/s) we can perform per dollar spent, and how effectively we use our computing hardware (Hardware Utilisation Rates). In simpler terms, these improvements mean we can now do more complex AI calculations for less money, making AI development more accessible and efficient.
Model Size
As AI models grow more sophisticated, they require diverse, clean, and labelled datasets. Acquiring such data offers immense competitive advantages, including the ability to block competitors from accessing it. This need is particularly acute for datasets that help train models to understand nuanced human behaviour and complex real-world scenarios. As an example, although GPT-4 followed GPT-3, from an evolutionary perspective, the jump between the two is too high. It would be like hominids jumping straight from the Australopithecus to the Homo Erectus, skipping many intermediate steps.
The growing complexity and size of models have raised barriers to entry. Creating new models now demands substantial investment, often millions of dollars. This situation limits competition to a few, large, well funded entities.
What is the alternative, you might ask? There’s not much you can do, at least for the time being. This is Technology Sector with Steel Industry Characteristics.
To summarise, high quality data is expensive, software and hardware optimisation results in more efficient model training (as measured in FLOP/s per dollar), but the overall cost to train a model from scratch is increasing to the point that small firms can no longer afford to accomplish this.
Data Network Effects
Data benefits from what's known as 'Network Effects.' Here's how it works: More data improves models, leading to more useful applications. These improved applications attract more users, who generate even more data. It's a self-reinforcing cycle that enhances the value and effectiveness of AI technologies.
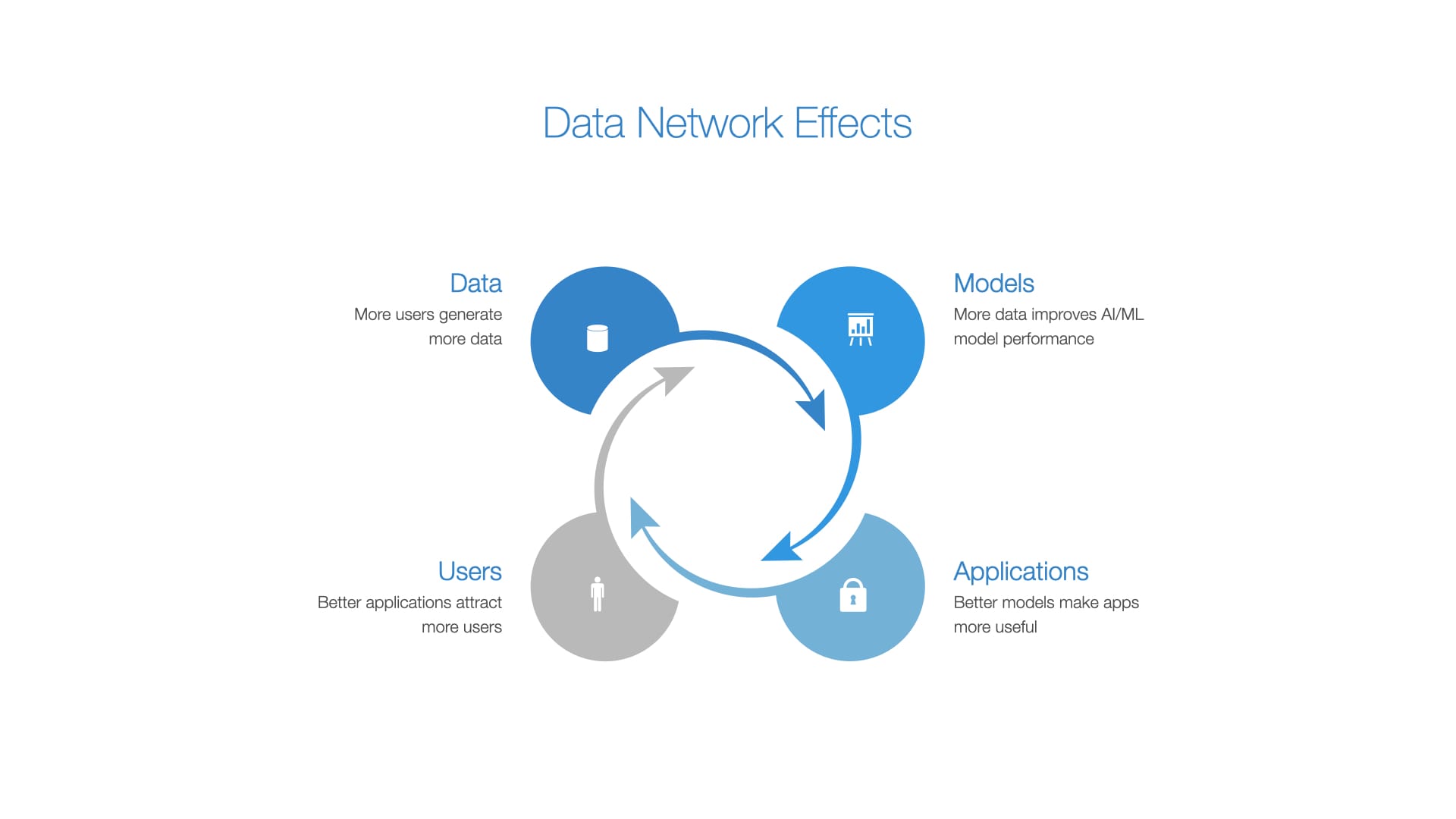
Businesses with large-scale data collection mechanisms can therefore benefit disproportionately from two trends - they can leverage declining per-unit cost to train models leading to rapid innovation, while also capitalising on their unique data assets to create AI applications that are difficult to replicate. This deepens their moat, making it difficult or nearly impossible for startups or other new entrants to match the data volume or model effectiveness.
For startups, the smart thing to do is not to fight the FAANG-esque companies head on, but to hide in the woods and build a niche kingdom. This isn't a groundbreaking thought - this method of competing is the staple of MBA strategy courses.
One possible way to circumvent this vice grip on data that large firms have is to use synthetic, and/or public data.
Synthetic data is created through algorithms that:
- Mimic Real-World Data: They replicate the statistical properties and patterns observed in actual data.
- Ensure Relevance: The generated data maintains the relationships found in real datasets, making it valuable for training AI models
As previously available public data sources become less accessible, either disappearing, becoming outdated, or moving behind paywalls, 'synthetic data' emerges as a possible solution. Synthetic data, although artificially generated, closely mimics real-world data, helping to bridge the gap where actual data is scarce. It also removes many of the risks and concerns around privacy (GDPR, CCPA etc), especially in fields where data is scarce or sensitive—such as in healthcare, finance, and security.
While the use of synthetic data is not without its tradeoffs, it can accelerate innovation by providing a rich source of information for training models and testing hypotheses.
To summarise, while the marginal cost of making predictions continues to fall, the overall cost of the inputs is increasing as a function of the size and scale of the models being deployed.
Strategies for Venture Capital Investors
All that being said, I don't find the three definitions from above (point, application, and system solutions) alone to be useful to understand where to invest, or what to build my investment thesis on.
For that, I fall back onto my 2x2 Matrix, assessing the scope of problems, and the level of innovation that a firm (or a startup) operates at.
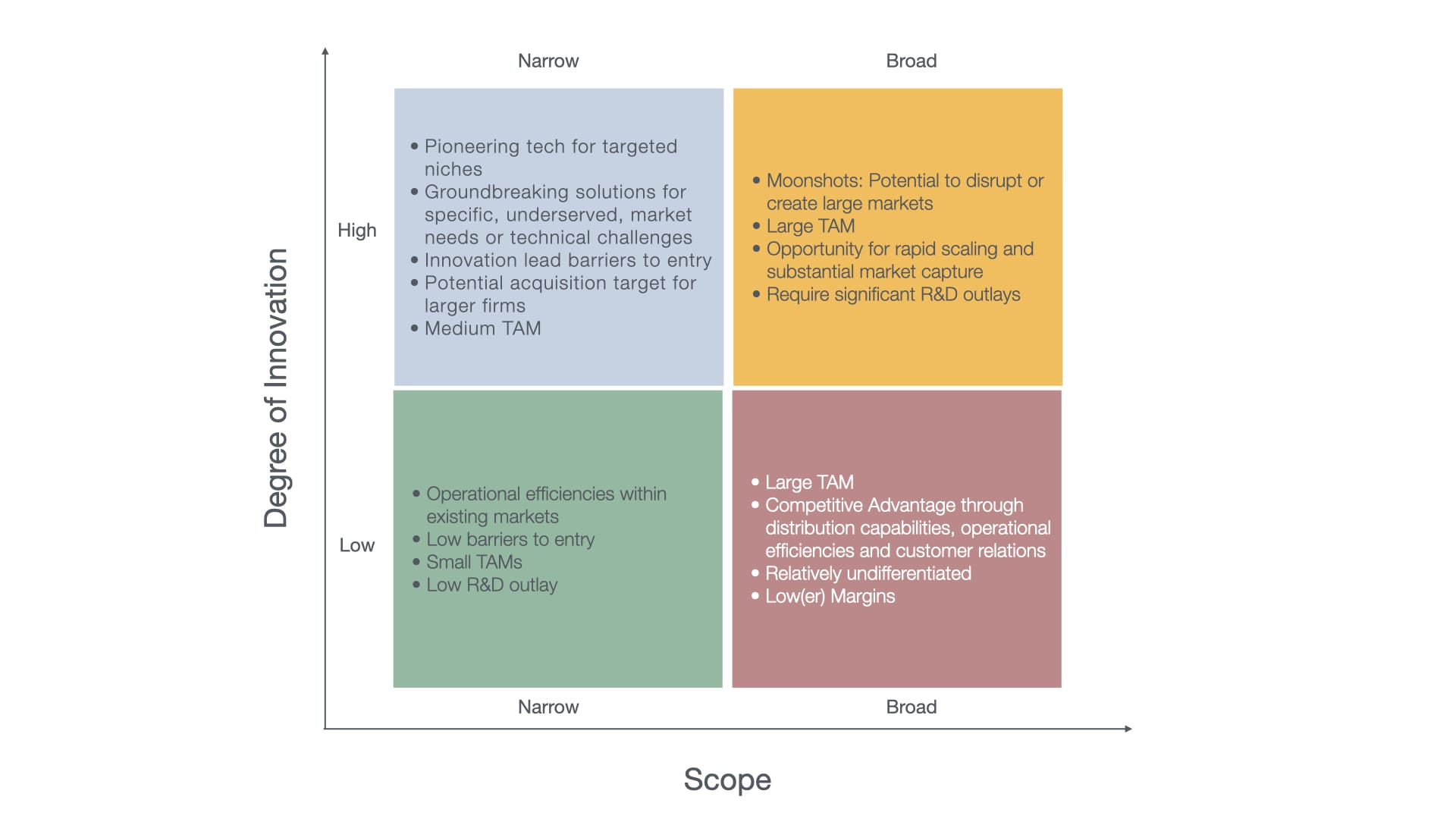
For a Venture Capital firm, the best quadrants to focus on would be:
1. High Innovation, Broad Scope: These have large TAMs, and the potential for outsized returns that VC look for (given their cost structures and the 2-20 model).
2. High Innovation, Narrow Scope: Smaller TAMs, can go on to become a niche leader, and a potential acquisition target in the future.
I would consider the Low Innovation, Broad Scope set to be the domain of a large Fortune 500 tech firm that makes steady returns based on the strength of its sales force, operational efficiencies and customer service quality.
The Low Innovation, Narrow Scope set just wouldn't be suitable for VC firms, given the economics of the previously mentioned 2-20 model. For Corporate VCs or acquisitive companies, these could present a potential to enter a niche it doesn't have a presence in.
Closing Remarks and Predictions
Strategy is both the set of choices taken and those not taken. As AI offerings get more sophisticated, moving away from Point Solutions to eventually System Solutions, the tech industry will go through a variety of challenges and opportunities, some of which will pay off, and some won't.
On that point, AI isn't unlike previous waves of technology.
While there is talk of 'one person' unicorns, my own experiences creating AI-based products tell me that while we are very close, we are not there yet. Large firms still have the advantage of having deep resource pools, which if deployed well can provide a sustainable moat well into the future. Some incumbents will no doubt make unforced errors and will fall off the wagon. The other principles of building a successful business remain the same.
We can make a few reasonable predictions on what to expect.
First, let us list out the complements to an AI-based product, including foundational models. A non-exhaustive list would be:
- Data
- Clean
- Labelled
- Hardware
- GPUs
- TPUs
- Software Frameworks
- Eg: PyTorch, TensorFlow
- Developer Ecosystem
Predictions
- Expansion of Open-Source AI Libraries: As we have already seen with Meta releasing, and Open Sourcing Llama3, firms will strategically open-source foundational AI models to accelerate innovation within the developer community. This action enhances the ecosystem by attracting a broader base of contributions, which in turn improves the technology and reduces costs through collective problem-solving. Open Source is by no means a form of altruism, it's the good ol' "Subsidise Your Complement" strategy. Meta's core product is your attention, which it monetises by serving ads. Anything else is a complement to that, and it is smart strategy to subsidise it.
- Strategic Hardware Differentiation by Chip Manufacturers: Companies like Nvidia and Intel will invest heavily in differentiating their AI hardware products through proprietary technologies and exclusive partnerships.
- Rivalry Through Standards and Open Source: Software firms will push for open standards and open-source projects to counteract the hardware-based differentiation strategy of chip manufacturers.
- Shift Towards Proprietary Datasets and Advanced AI Functions: As the availability and quality of training data become critical bottlenecks, companies and investors will increasingly engage in strategic acquisitions of data-rich companies, not for their products but for their underlying data assets. While basic AI functionalities become commoditised, companies will protect and enhance proprietary datasets and advanced AI capabilities, which are harder to replicate and offer significant competitive advantages.
- Emergence of Cross-Licensing and Revenue Sharing Agreements: As tensions rise between software and hardware providers in the AI space, we will see an increase in cross-licensing and revenue-sharing agreements to mitigate conflict and ensure mutual benefits.
- Dominance of Niche Application Solutions: AI startups focusing on niche application solutions will find significant success by addressing specific industry pain points that are overlooked by larger players, thereby establishing strong market positions within these niches.
- Aggressive M&A Activities to Control Key AI Technologies: Especially of the High Innovation, Narrow Scope type of firms.
- Emergence of Synthetic Data Champions: Startups that specialise in generating high-quality synthetic data will emerge as key players, enabling wider AI adoption across sectors where data privacy, availability, or quality has been a barrier.
Further Reading
- Power and Prediction: The Disruptive Economics of Artificial Intelligence, by Ajay Agarwal at https://amzn.to/4d8EqTR
- Joel on Software, by Joel Spolsky at https://amzn.to/3UdmOxx
- Information Rules: A Strategic Guide to the Network, by Carl Shapiro and Hal Varian at https://amzn.to/3JzReoO
Member discussion